The dollar value of legitimate ecommerce orders incorrectly declined by fraud prevention software (false positives) is materially larger than the dollar value of fraud those tools prevent. The cost is structural, not anecdotal, and it gets worse as a merchant scales. The reasons are mechanical: the way most fraud prevention software is built (rules, models, identity signals, single-transaction views) does not match the shape of real merchant growth (more volume, more variation, new markets, new payment methods, new device patterns).
The cost picture
- $443B annually in global ecommerce false declines (Datos Insights / Aite-Novarica), compared with roughly $48B in actual ecommerce credit card fraud losses globally — meaning false declines cost the ecosystem roughly 9x more than the fraud the tools were built to stop.
- US issuer-side false declines are estimated at $213B/year (Datos Insights).
- US merchants pay $4.61 in total cost for every $1 of fraud (LexisNexis True Cost of Fraud 2025) — most of that cost is operational overhead, not the fraud loss itself.
- 3.2% of total annual ecommerce revenue is lost globally to payment fraud (MRC 2025 Global Payments and Fraud Report) — the false positive number is a multiple of that.
- Customer-experience drag: 36% of US retail respondents and 37% of US ecommerce respondents cite poor user experience as the primary driver of abandonment at new-account creation (LexisNexis 2025).
- Returning-customer churn from one false decline: industry research consistently finds that a meaningful share of falsely declined customers do not return to the merchant for future purchases.
Why ecommerce fraud prevention tools generate false positives at scale
Eight structural reasons, ordered roughly from most upstream (data) to most downstream (deployment).
1. Imbalanced training data. Fraud is rare. In the median ecommerce business, fraudulent transactions are well under 1% of total transactions. Machine learning models trained on that distribution are penalized heavily for missing the rare positive class, which pushes them toward sensitivity (catch as much fraud as possible) at the expense of specificity (don’t flag legitimate customers). The optimization trade off baked into model training shows up as false positives in production.
2. Static rules cannot encode nuance. Rules like “decline if AVS mismatch” or “decline if velocity > 5 in 1 hour” reduce judgment to thresholds. They don’t distinguish a gift purchase (different shipping address) from a stolen card, or a parent buying for a college student (new device, new IP) from an account takeover. Rules are auditable and predictable, which is their value, but they cannot encode the context that separates an unusual legitimate behavior from an unusual fraudulent one.
3. Single-transaction views miss the relationship. Most fraud prevention software evaluates a transaction at checkout, using the signals available at that moment. A returning customer with five years of clean orders and a recent customer-service interaction looks the same as a brand-new account if the only signals visible are device, IP, BIN, AVS, and cart contents. The decisioning model is missing context that, if connected, would resolve the ambiguity.
4. Generic models miss merchant-specific normal. A network-trained model averages behavior across thousands of merchants. A $400 average order is suspicious at a commodity retailer and routine at a luxury brand. A single customer ordering twelve units is suspicious for a small ticket grocer and routine for a B2B office supplier. Generic calibration creates predictable error: the model is most wrong precisely on the merchants whose customers don’t fit the average.
5. Identity signals are unstable. Device fingerprints rotate as users upgrade phones. IPs change as customers move between networks, use carrier-grade NAT, or travel. Email addresses get aliased. Legitimate identity churn looks similar to evasion-by-design. The more aggressively a fraud system weights identity stability as a positive signal, the more it punishes customers whose identity legitimately changes.
6. Velocity thresholds calibrated at low volume break at higher volume. A merchant processing 1,000 transactions a day calibrates velocity rules to that volume. At 100,000 transactions a day, the same rules generate disproportionately more flags because legitimate behavior at scale produces more outliers, not because any individual customer is more suspicious. The threshold did not move; the world the threshold lives in did.
7. Cross-channel signals are siloed. A customer who just returned an item, contacted support twice, or completed a 3DS challenge yesterday should be evaluated differently from a fully cold customer. Most fraud software does not have visibility into post-purchase signals, support interactions, or marketing engagement. The signals exist somewhere in the merchant’s stack; they don’t reach the decisioning layer.
8. Manual review is expensive and slow. When a model produces an uncertain score, the conventional fallback is manual review. Manual review at meaningful scale is operationally expensive (analyst headcount, training, latency, queue management) and inconsistent (different analysts apply different judgment). Most merchants under-resource review, which means borderline transactions get blanket-declined to keep the queue manageable.
Why scaling with order volume makes the problem worse
Three reinforcing dynamics.
More legitimate variation. A growing business adds new customer segments, new geographies, new device profiles, new payment methods. Each addition broadens the surface area of “normal.” Fraud tools calibrated against an older, narrower distribution will flag the new patterns as anomalies. The fix requires retuning, which most merchants do less often than the rate at which their business is changing.
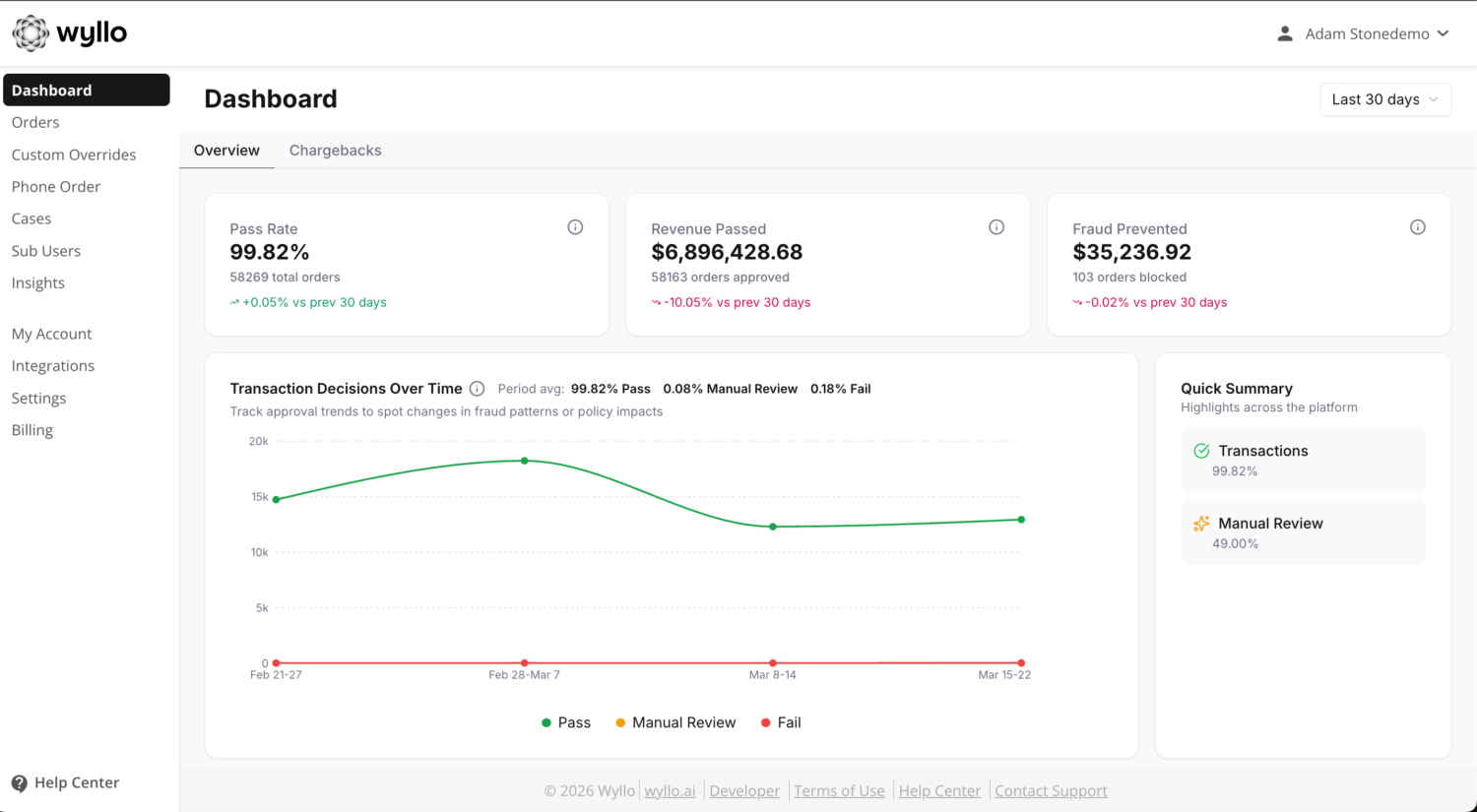
More edge-case volume. Even when false positive rates stay constant in percentage terms, the absolute number of declined legitimate customers grows linearly with order volume. A 2% false decline rate is 200 declines per day at 10,000 transactions; at 100,000 transactions it is 2,000 declines per day. The team handling appeals, customer service complaints, and CLV recovery faces a step-change problem at scale.
Diminishing returns on the same playbook. Most fraud prevention software is sold and deployed with a “set it up once, retune occasionally” cadence. The structural reasons in the previous section get worse as volume scales, which means the same configuration produces worse and worse outcomes over time even when the merchant is doing everything the same way.
Why this is a structural problem with ecommerce fraud prevention tools, not a vendor problem
The root cause is shared across the category. Any ecommerce fraud prevention tool that (a) trains models on imbalanced data, (b) decides at the transaction rather than the relationship, (c) treats identity stability as a positive signal, (d) cannot see cross-channel context, and (e) calibrates velocity to a point-in-time view of volume will produce false positives at scale. Some vendors do parts of this better than others; none has solved the underlying mismatch between how fraud prevention software is designed and how merchant growth actually behaves.
How to reduce false positives without increasing chargebacks
The premise that lower false positives must mean higher chargebacks is wrong in general and wrong in detail. It holds only if the decisioning system is binary (accept or decline) and signal-poor. Both assumptions can be replaced.
Replace binary decisions with graduated friction. A graduated path uses 3DS challenges, OTP step-ups, or in-flow verification for ambiguous transactions, not declines. The customer who is who they say they are completes the step-up. The customer who is not, drops off. The merchant captures the marginal transaction value without absorbing the chargeback risk.
Add positive signals alongside negative ones. Most ecommerce fraud prevention tools are tuned to score risk. Few are tuned to score trust. Returning customer, account age, prior order history, prior 3DS success, prior support interaction without dispute — these are positive signals that a model can use to elevate ambiguous transactions out of the decline path. Adding positive context is usually cheaper than improving negative-signal precision.
Connect cross-channel signals to the decisioning layer. Customer service tickets, return history, marketing engagement, post-purchase activity. These signals already exist in the merchant’s stack. The work is to surface them at the decisioning moment, not to generate new ones. The payoff is highest on the transactions that today require manual review.
Calibrate to merchant-specific normal. Generic models are a starting point, not an end state. The largest false positive gains usually come from re-tuning thresholds against the merchant’s own customer behavior — order size distribution, geographic mix, device patterns, payment method preferences. The tuning loop should be continuous, not annual.
Use 3DS strategically rather than universally. Mandatory 3DS at checkout increases liability protection but also drives meaningful drop-off (issuer-side abandonment, fatigue declines, push-notification timeouts). Targeted 3DS — applied to ambiguous transactions rather than all transactions — captures the liability shift where it matters without the universal friction cost.
Build feedback loops from manual approvals. Most fraud systems learn from chargebacks, which are slow signals (months after the transaction). Manual approval and decline decisions are fast signals (within hours) and produce labeled data the model would otherwise not see. Closing the loop from manual review back into model training is one of the highest-leverage investments most fraud teams underinvest in.
What the future should look like for ecommerce fraud prevention tools
The false positive problem reduces to a context problem. A binary decline-or-accept decision at a single point in the customer journey, made from a narrow signal set, will always have a false positive rate that grows with scale. The transactions that fraud prevention software gets wrong are the transactions where the signal set was too thin to support the decision.
The durable answer is not faster decisions on thinner signals. It is the same decision speed on richer context — context that connects identity, behavior, merchant-specific norms, and post-purchase signals so the decisioning layer can act on what is actually happening rather than what the checkout snapshot looks like in isolation.
Reducing false positives without increasing chargebacks is not a trade off to manage. It is a context problem to solve.